
Quality Control: Assignment 7
As you all may have noticed, it is easy to get a lot of junk answers from MTurk. You are hiring anonymous workers and you are paying them a few cents for their time. I don’t know about you, but based on all of my cynical models of human behavior, I would absolutely expect that you get 100% crap results back. But the truth is, you don’t. You get a lot of really legitimate work from a lot of very sincere workers, you just need to make some efforts to tease apart the good from the bad, which isn’t always trivial. This is why we can dedicate a whole course to studying crowdsourcing.
So, this week, we will attempt to answer two big questions:
- How good are my workers? Which workers are reliable and which ones appear to be incompetent, lazy, and/or inebriated?
- How do I combine the (likely conflicting) labels from multiple workers in order to accurately label my data?
In class, we have discussed three different quality estimation methods to answer these questions:
- Majority vote: A label is considered ‘correct’ if it agrees with the majority, and all votes are equal. (Pure democracy!)
- Confidence-weighted vote: A label is considered ‘correct’ if it agrees with the majority, but all workers are not equal. A worker’s weight is proportional to their accuracy on your embedded gold-standard questions. (Elitist republic!)
- Expectation maximization : A label’s ‘correctness’ is determined using an iterative algorithm, which uses the estimated quality of the worker in order to infer the labels, and then the estimated labels in order to infer the quality of the worker. (Some new-fangled solution to politics…?)
For this assignment, you will run the first two algorithms and provide a brief analysis comparing them to each other. Besides, you will filter out “good” workers and create a new qualification type of your own as another good way of quality control. The data you will be using are the results from a real mTurk project. You can work independently or in pairs.
Since EM is a more advanced algorithm, we will only require you to walk through a toy example. If you are interested in machine learning, and want to understand this concept better, you are welcome and encouraged to run it on the same real mTurk project data and earn some extra credits!
Please first download the skeleton python file homework7.py. Since we have set up an autograder for this assignment (which will take in as input the .py), we will not be providing a Colab notebook. However, if you wish, you may copy the Python code into your own Colab notebook and code from there. Then you can export the notebook as a .py before submititng.
Part 1: Aggregation methods
Data
The data you will be using are the results from a real mTurk project Adjectives and Attribute Matching with a more complicated result file. You can download it as hw7_data.csv. These are real data collected for research purposes.
In the skeleton python file, we have put one line of code mturk_res = pd.read_csv('hw7_data.csv') in the main function for you to read the data using the python package pandas. Please do not change it and use this mturk_res as input to all the functions below with same the argument name.
Each HIT gives worker a certain attribute, its exact description, some example adjectives, and lets them judge for an additional several adjectives if each of them could describe that attribute.
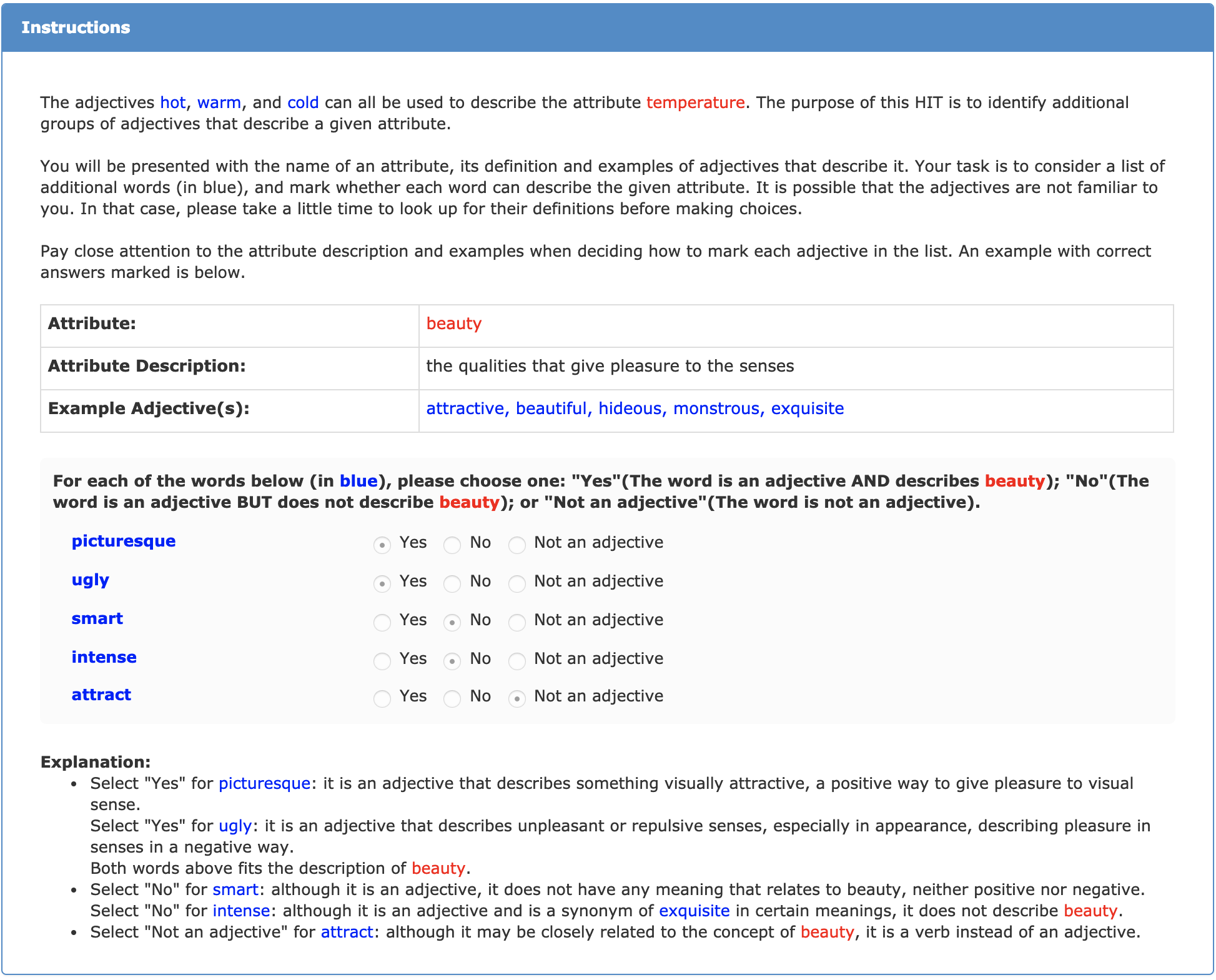
Below is a screenshot of the HIT instructions (same across all HITs) that worker can see. To better understand this project, please take a close look at these instructions.
And below is a screenshot of an example that worker would see and need to complete after reading the instructions.
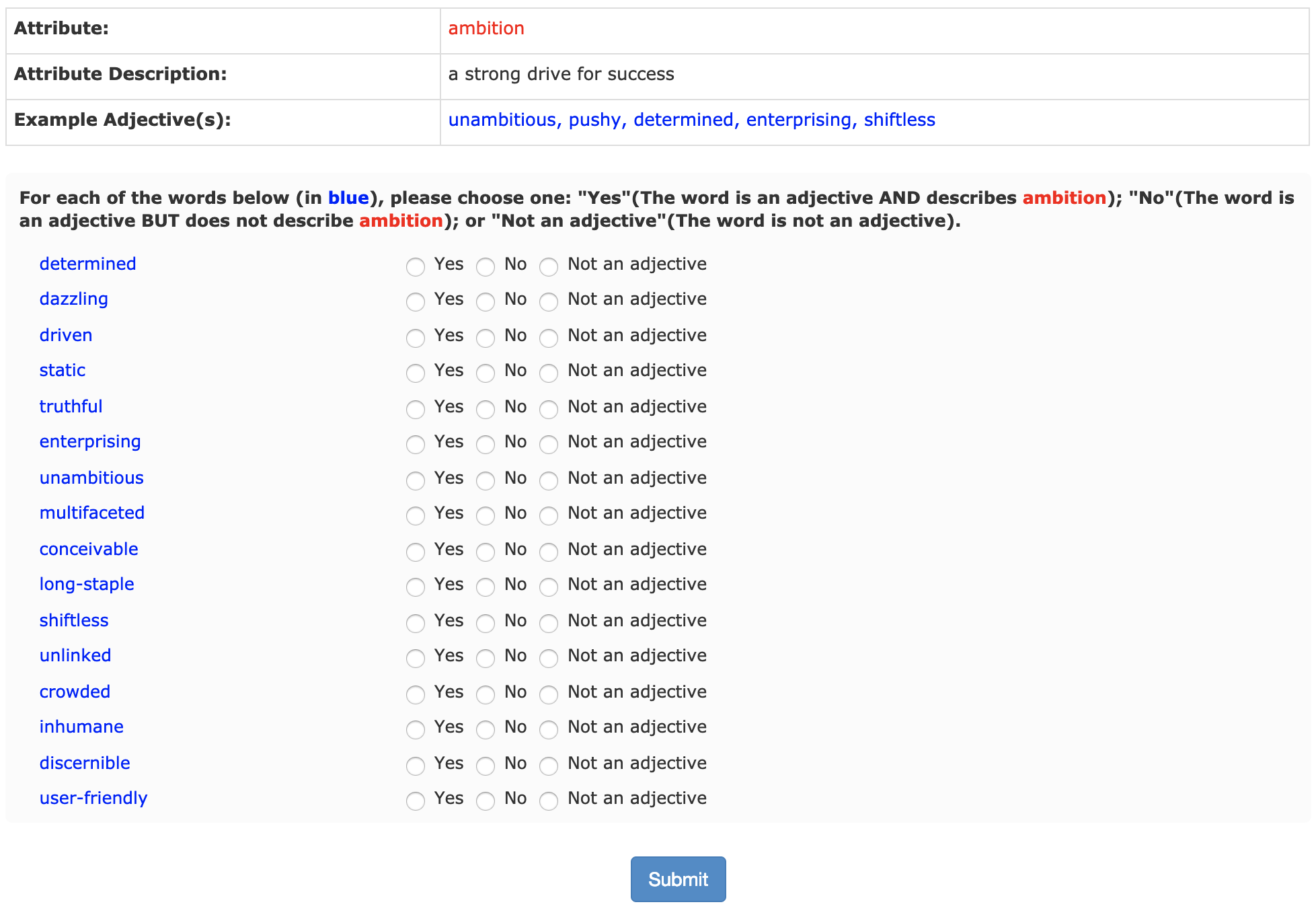
The content for each task changes according to the csv file uploaded to create the batch.
To simplify things, we treat “Yes” as labeled TRUE while “No” or “Not an adjective” both as labeled FALSE. Note that “Not an adjective” will also be abbreviated as “Naa” in this assignment.
For each assignment, there are up to 16 number of adjectives for worker to label, where up to 10 are the ones we need answers, up to 5 for embedded positive quality control (the answer is supposed to be “Yes”, i.e. TRUE), and 1 for negative quality control (the answer is supposed to be “No” or “Not an adjective”, i.e. FALSE). Each assignment are supposed to be done by 3 workers, and those 16 words are shown in the random order for each worker.
In the data file, the fields with column names Input.adj_* are the 10 adjectives we need answers; Input.pos_qual_ctrl_* are the 5 for positive quality controls and Input.neg_qual_ctrl is the 1 for negative quality control. The columns that in the same format with Input replaced to Answer are the answers we got from workers.
Notice: For all the function return values and output files in this assignment, you should only contain relevant things for the words in the Input.adj_* columns, ignoring the embedded quality control columns.
Majority vote
Majority vote is probably the easiest and most common way to aggregate your workers’ labels. It is simple and gets to the heart of what “the wisdom of crowds” is supposed to give us - as long as the workers make uncorrelated errors, we should be able to walk away with decent results. Plus, as every insecure middle schooler knows, what is popular is always right.
-
First, use majority vote to assign labels to each of the attribute-adjective pair in the data.
Let’s use \(\textit{labels}\) to refer to the dictionary keeping the label of each attribute-adjective pair and use \(p\) to denote an attribute-adjective pair. Then \(\textit{labels}[p]\) is the label we assign to \(p\). So we have
$$\textit{labels}[p] = \text{majority label for } p.$$ You will implement a function
majority_vote(mturk_res)that takes in mTurk result data read from the CSV file we give, return a list of three-element tuples in the format(attr_id, adj, label)sorted alphabetically given the same column order.In your
mainfunction, you should output the returned tuples into a 3-column CSV file calledoutput1.csvwith the same column names mentioned above. -
Now, you can use the pair labels you just computed to estimate a confidence in (or quality for) each worker. We will say that a worker’s quality is simply the proportion of times that that worker agrees with the majority.
Let’s define some more notation. This is, after all, a CS class. We have a quota to meet for overly-mathifying very simple concepts, to give the appearance of principle and rigor.
Lets call \(\textit{qualities}\) the dictionary that we build to hold the quality of each worker. We’ll call the \(i\)th worker \(w_i\) and we’ll use \(\textit{pairs}[w_i]\) to represent all the attribute-adjective pairs for which \(w_i\) provided a label. We’ll let \(l_{pi}\) represent the label, i.e.
TRUEorFALSE, that \(w_i\) assigns to the pair \(p\). Then we calculate the quality of a worker as:$$\textit{qualities}[w_i] = \frac{1}{|\textit{pairs}[w_i]|} \cdot \sum_{p\in \textit{pairs}[w_i]} \delta(l_{pi}\textit{ == labels}[p]).$$ Here, \(\delta(x)\) is a special function which equals 1 if \(x\) is true, and 0 if \(x\) is false.
You will implement a function
majority_vote_workers(mturk_res, votes)that takes in mTurk result data read from the CSV file we give and the returned value from the previousmajority_vote(mturk_res)function, return a list of two-element tuples in the format(worker_id, quality)sorted alphabetically by the worker_id. Please keep 3 decimal points for your computation.In your
mainfunction, you should output the returned tuples into a 2-column CSV file calledoutput2.csvwith the same column names mentioned above.
Weighted majority vote
Majority vote is great: easy, straightforward, fair. But should everyone really pull the same weight? As every insecure student knows, whatever the smartest kid says is always right. So maybe we should recalibrate our voting, so that we listen more to the better workers.
-
For this, we will use the embedded quality control test questions. We will calculate each worker’s quality to be their accuracy on the test questions. E.g.
$$\textit{qualities}[w_i] = \frac{1}{|\textit{gold_pairs}[w_i]|} \cdot \sum_{p\in \textit{gold_pairs}[w_i]} \delta(l_{pi}\textit{ == gold_labels}[p]).$$ Remember, you can know whether or not an attribute-adjective pair in your CSV file corresponds to a gold test question by checking the
*_qual_ctrl*columns.You will implement a function
weighted_majority_vote_workers(mturk_res)that takes in mTurk result data read from the CSV file we give, return a list of two-element tuples in the format(worker_id, quality)sorted alphabetically by the worker_id. Please keep 3 decimal points for your computation. You should ignore quality control columns if either itself or its answer is absent, i.e.NaN.In your
mainfunction, you should output the returned tuples into a 2-column CSV file calledoutput3.csvwith the same column names mentioned above. -
You can use these worker qualities to estimate new labels for each of the attribute-adjective pairs in the data. Now, instead of a every worker getting a vote of 1, each worker’s vote will be equal to their quality score. So we can tally the votes as
$$\textit{vote}[p][l] = \sum_{w_i \in \textit{workers}[p]} \delta(l_{pi}\textit{ == }l)\cdot \textit{qualities}[w_i]$$ where \(\textit{vote}[p][l]\) is the weighted votes for assigning label \(l\) to attribute-adjective pair \(p\) and \(\textit{workers}[p]\) is just lists all of the workers who labeled \(p\). Then
$$\textit{labels}[p] = l \text{ with max } \textit{vote}[p][l].$$ You will implement a function
weighted_majority_vote(mturk_res, workers)that takes in mTurk result data read from the CSV file we give and the returned value from the previousweighted_majority_vote_workers(mturk_res)function, return a list of three-element tuples in the format(attr_id, adj, label)sorted alphabetically given the same column order.In your
mainfunction, you should output the returned tuples into a 3-column CSV file calledoutput4.csvwith the same column names mentioned above.
Part 2: The EM algorithm
The data aggregation algorithms you used above were straightforward and work reasonably well. But they are of course not perfect, and with all the CS researchers out there, all the Ph.Ds that need to be awarded and all the tenure that needs to be got, its only natural that many fancier, mathier algorithms have arisen.
We discussed the expectation maximization (EM) algorithm in class as a way to jointly find the data labels and the worker qualities. The intution is “If I knew how good my workers were, I could easily compute the data labels (just like you did in step 2 of weigthed vote) and if I knew the data labels, I could easily compute how good my workers are (just like you did in step 1 of weighted vote). The problem is, I don’t know either.” So the EM solution is to guess the worker qualities, use that to compute the labels, then use the labels we just computed to reassign the worker qualities, then use the new worker qualities to recompute the labels, and so on until we converge (or get bored). This is one of the best-loved algorithms in machine learning, and often appears to be somewhat magic when you first see it. The best way to get an intuition about what is happening is to walk through it by hand. So for this step, we will ask you do walk through 3 iterations of EM on a toy data set.
You will implement a function em_vote(rows, iter_num) that takes in the list of result rows read from the toy dataset and a number of iterations, and returns two lists:
labels: list of two-element tuples in the format(url, label)sorted alphabetically by the url orderworker_qual: list of worker qualities Some skeleton functions are given, which should help with your understanding of the algorithm structure.
In your main function, you should output the returned tuples after 3 iterations into a 2-column CSV file called output5.csv with the same column names mentioned above.
You can refer to the lecture slides as a guide. The numbers are slightly different, but the process is idenitcal. If you are super ambitious, you are welcome to delve into the depths of the original 1979 paper describing the use of EM for diagnosing patients.
Extra credit
If you are super ambitious and/or super in want of extra credit, you can code and run EM on the data on the Adjectives and Attribute Matching result data. Add a function called em_vote_ec(rows, iter_num) to the same .py file, and have it output the returned tuples after 3 iterations into a 2-column CSV called output_ec.csv.
Part 3: Qualified workers
Sometimes, the projects you need for crowd-sourcing might needs better understanding or attention from people, or requires tons of data for people to label with limited budget. In that case, you might not want risk having people that are totally random, but the ones who actually gets what you are trying to do.
The Adjectives and Attribute Matching project we are dealing with in this assignment fits perfectly to those conditions. So we decided to go with this other quality control method, which is to use a test batch to select “good” workers that can do our tasks with high quality in general and only allow them to be the workers for our full batch data. The data you have access to in this assignment is actually a test batch that we use to do the selection.
How do we define as “good” workers? In our case, we need a worker to satisfy the following conditions:
- Completed >= 5 number of HITs;
- Of all the completed HITs, the percentage of HITs that satisfy the following condition must >= 75%:
- Must be correct about the negative quality control adjective;
- Must be correct about at least 4 out of 5 positive quality control adjectives;
You can of course try other criterions and see how things are different if you are interested and discuss in the report, but not for python code submission purposes.
You will implement a function select_qualified_worker(mturk_res) that takes in mTurk result data read from the CSV file we give, return a list of two-element tuples in the format (worker_id, percentage) sorted alphabetically by the worker_id. The percentage here is the percentage of completed HITs computed for the second condition above. Please keep 3 decimal points for your computation.
In your main function, you should output the returned tuples into a 2-column CSV file called output6.csv with the same column names mentioned above.
Additionally, create a new qualification type and add the “good” workers to it according to your results. You can access a worker’s page by going to https://requester.mturk.com/workers/WORKERID. Take a screenshot when you are done adding all the qualified workers.
Deliverables
-
homework7.py with your own codes added
Notice: Please DON’T put any print statements inside or outside any functions. Otherwise, you may lose all points for your python implementation. If you need to print anything for debugging for analyzing, please do that in your
mainfunction. -
All 6 required output CSV files from output1.csv to output6.csv
-
Report homework7.pdf
- Compare the majority and weighted majority labels from Part 1. If there are any differences, give 2 interesting examples on how they are different on some example attribute-adjective pairs. If there are no differences, discuss why could be the case.
- For the EM algorithm on toy data, discuss how worker quality and URL labels change for each of the 3 iterations.
- Screenshot of your own new qualification type with “good” workers added
- Share your thoughts on different quality control methods
Grading Rubric
This assignment is worth 100 points. The rubric for the assignment is given below.
- 25 points - Python file with required functions implemented. Your code should be readable enough that we can tell what you did, but does not need to conform to any particular interface.
- 40 points - 6 ouput CSV files in the required format.
- 35 points - Report with required details.
- Extra credit (10 points) - an extra function
em_vote_ecin the same Python file, and CSV results inoutput_ec.csvwith your EM implementation on our data.